
La popularité croissante de l'intelligence artificielle (IA) dans le monde d'aujourd'hui exige l'introduction de types de données de faible précision et la prise en charge matérielle de ces types de données afin d'améliorer les performances. Les modèles de faible précision sont plus rapides à calculer et ont une empreinte mémoire plus faible. Pour ces raisons, les types de données de faible précision sont préférés aux types de données 32 bits pour l'apprentissage de l'IA et l'inférence. Pour optimiser et prendre en charge ces types de données de basse précision, le matériel a besoin de caractéristiques et d'instructions spéciales. Intel les fournit sous la forme d'Intel® Advanced Matrix Extensions (Intel® AMX) et d'Intel® Xe Matrix Extensions (Intel® XMX) sur les processeurs Intel® et les GPU, respectivement. Parmi les formats 16 et 8 bits les plus utilisés, citons la virgule flottante IEEE 16 bits (fp16), bfloat16, les entiers 16 bits (int16), les entiers 8 bits (int8) et la virgule flottante Microsoft 8 bits (ms-fp8). Les différences entre certains de ces formats sont illustrées à la figure 1.
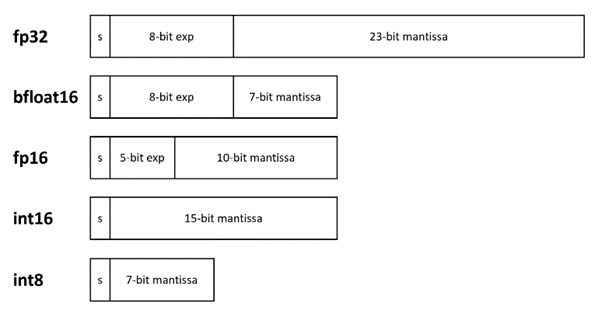
Figure 1. Diverses représentations numériques des types de données standard de l'IEEE. Le s représente le bit signé (0 pour les nombres positifs et 1 pour les nombres négatifs) et exp représente l'exposant.
Il existe différents paradigmes de programmation pour invoquer Intel AMX et Intel XMX sur leur matériel respectif. Cet article permettra de comprendre les différentes façons de les programmer, puis de démontrer les avantages de ces jeux d'instructions en termes de performances.
Intel® AMX et Intel® XMX
Intel AMX
Intel AMX est une extension de l'architecture du jeu d'instructions x86 (ISA) pour les microprocesseurs. Elle utilise des registres 2D, appelés tuiles, sur lesquels les accélérateurs peuvent effectuer des opérations. Il y a généralement huit tuiles dans une unité d'Intel AMX. Les tuiles peuvent effectuer des opérations de chargement, de stockage, d'effacement ou de produit de points. Intel AMX prend en charge les types de données int8 et bfloat16. Intel AMX est pris en charge par les processeurs Intel® Xeon® Scalable de 4ème génération (Figure 2).
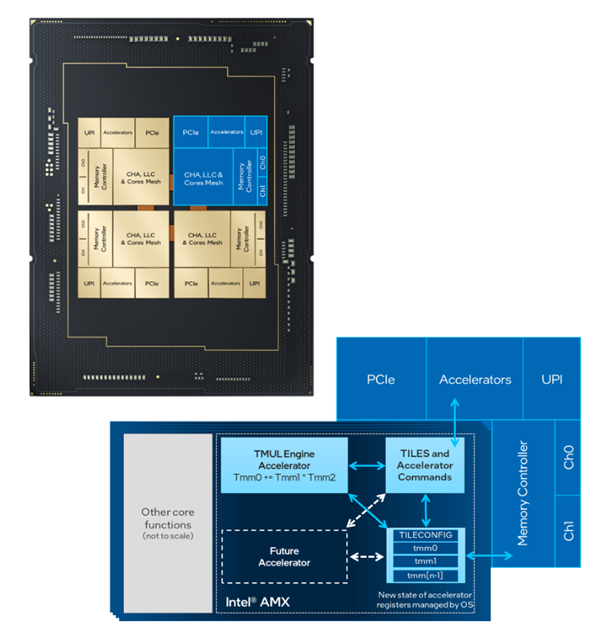
Figure 2. Intel® AMX dans les processeurs Intel® Xeon® Scalable de 4e génération
Intel XMX
Intel XMX, également connu sous le nom de Dot Product Accumulate Systolic (DPAS), est spécialisé dans l'exécution des instructions dot product et accumulate sur des réseaux systoliques 2D. Dans une architecture informatique parallèle, un réseau systolique est un réseau homogène d'unités de traitement de données étroitement couplées. Chaque unité calcule un résultat partiel en fonction des données reçues de ses voisins en amont, stocke le résultat en son sein et le transmet en aval. Intel XMX prend en charge de nombreux types de données, comme int8, fp16, bfloat16 et tf32, en fonction de la génération du matériel. Il fait partie de la série Intel® Data Center GPU Max ou Intel Data Center GPU Flex. La pile Intel® Xᵉ HPC 2 d'Intel Data Center GPU Max est abrégée en Xᵉ dans la figure 3. Stack est le terme utilisé alternativement pour les tuiles. Chaque Intel Data Center GPU Max est composé de huit Intel Xᵉ slices. Chaque tranche contient 16 cœurs Intel Xᵉ. Chaque cœur contient huit moteurs vectoriels et huit moteurs matriciels.

Figure 3. Intel® XMX dans Intel® Data Center GPU Max (anciennement connu sous le nom de code Ponte Vecchio)
Programmation avec Intel AMX et Intel XMX
Les utilisateurs peuvent interagir avec Intel XMX à différents niveaux : cadres d'apprentissage profond, bibliothèques dédiées, noyaux SYCL personnalisés, jusqu'aux intrinsèques de bas niveau. La figure 4 montre comment Intel AMX et Intel XMX peuvent être invoqués à travers différentes abstractions de codage, qui seront discutées ci-dessous. La boîte à outils Intel® oneAPI Base Toolkit 2024.0 est nécessaire pour tirer parti de ces extensions.
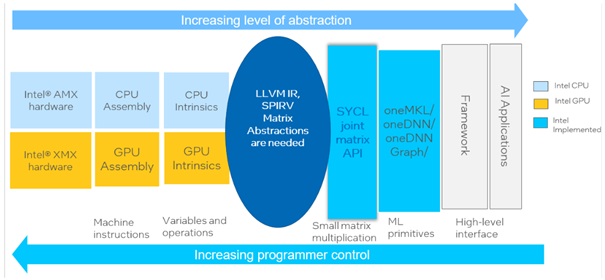
Figure 4. Abstractions de programmation pour le calcul matriciel
SYCL* Joint Matrix Extension
Joint matrix est une nouvelle extension SYCL* qui unifie des cibles telles que Intel AMX pour les CPU, Intel XMX pour les GPU et NVIDIA* Tensor Cores pour la programmation Tensor Hardware. Ces exemples de matrices conjointes SYCL montrent comment utiliser cette extension. Les utilisateurs qui souhaitent créer leurs propres applications de réseaux neuronaux peuvent utiliser joint matrix, qui a un niveau d'abstraction inférieur à celui des frameworks comme TensorFlow* et des bibliothèques comme Intel® oneAPI Deep Neural Network Library (oneDNN) et Intel® oneAPI Math Kernel Library (oneMKL). Elle fournit une interface unifiée qui est non seulement portable, mais qui bénéficie également des performances maximales que les différents matériels peuvent offrir. La matrice commune offre des capacités de performance, de productivité et de fusion ainsi qu'une portabilité sur différents matériels tensoriels, éliminant ainsi la nécessité de maintenir des bases de code différentes pour chaque plateforme matérielle.
Le terme "matrice commune" souligne le fait que la matrice est partagée par un groupe d'éléments de travail et qu'elle n'est pas propre à chaque élément de travail (figure 5). Bien que le champ d'application du groupe soit ajouté en tant qu'élément supplémentaire de la dans la syntaxe de matrice conjointe SYCL, seule la portée du sous-groupe est prise en charge dans l'implémentation actuelle. Certaines des fonctions nécessaires pour effectuer des opérations courantes sur les matrices, à savoir le chargement, le stockage et l'opération "multiplier et ajouter", sont représentées par joint_matrix_load, joint_matrix_store et joint_matrix_mad respectivement. Ils appellent à leur tour les intrinsèques Intel AMX ou Intel XMX de niveau inférieur, en fonction du matériel sur lequel le programme s'exécute. La fonction joint_matrix_load charge les données de la mémoire vers les tuiles/registres 2D, joint_matrix_store stocke les données dans la matrice accumulatrice depuis les tuiles 2D vers la mémoire, et joint_matrix_mad effectue l'opération de multiplication sur les deux matrices, accumule le résultat avec la troisième matrice et renvoie le résultat.

Figure 5. API communes de la matrice de jointure SYCL*
Intel® oneAPI Deep Neural Network Library (oneDNN) et Intel® oneAPI Math Kernel Library (oneMKL)
Intel® oneAPI Deep Neural Network Library (oneDNN) et Intel® oneAPI Math Kernel Library (oneMKL) utilisent Intel AMX et Intel XMX par défaut sur les processeurs Intel (à partir de la 4ème génération de processeurs Intel Xeon Scalable) et Intel Data Center GPU Max, respectivement. L'utilisateur de oneDNN doit s'assurer que le code utilise des types de données supportés par Intel XMX, et la bibliothèque oneDNN doit être construite avec
Support GPU activé. L'exemple matmul_perf fourni avec oneDNN invoquera Intel AMX et Intel XMX lorsqu'il sera compilé de manière appropriée. D'autres exemples oneDNN sont disponibles ici. Un exemple simple de oneMKL est disponible ici.
Analyse des performances pour Intel AMX
Comparons la multiplication matricielle effectuée sur fp32 standard par rapport à bfloat16. Le benchmark que nous utilisons est essentiellement une simple enveloppe pour les appels répétés à GEMM. Sur la base de notre compilation, nous pouvons passer les options suivantes:
• La version Intel® Math Kernel Library (Intel® MKL) du noyau GEMM
• GEMM à simple ou double précision (SGEMM/DGEMM)
• Le nombre de threads (NUM_THREADS) à utiliser
• La taille (SIZE_N) des matrices à multiplier.
Le code de référence prend la taille du problème, alloue de l'espace pour les matrices C = A x B, initialise les matrices A et B avec des données aléatoires, appelle GEMM une fois pour l'initialisation, fait des appels consécutifs à GEMM pour un nombre prédéfini de fois, et mesure le temps d'exécution de ce dernier. Nous pouvons constater que bfloat16 est plus performant que fp32 (figure 6).
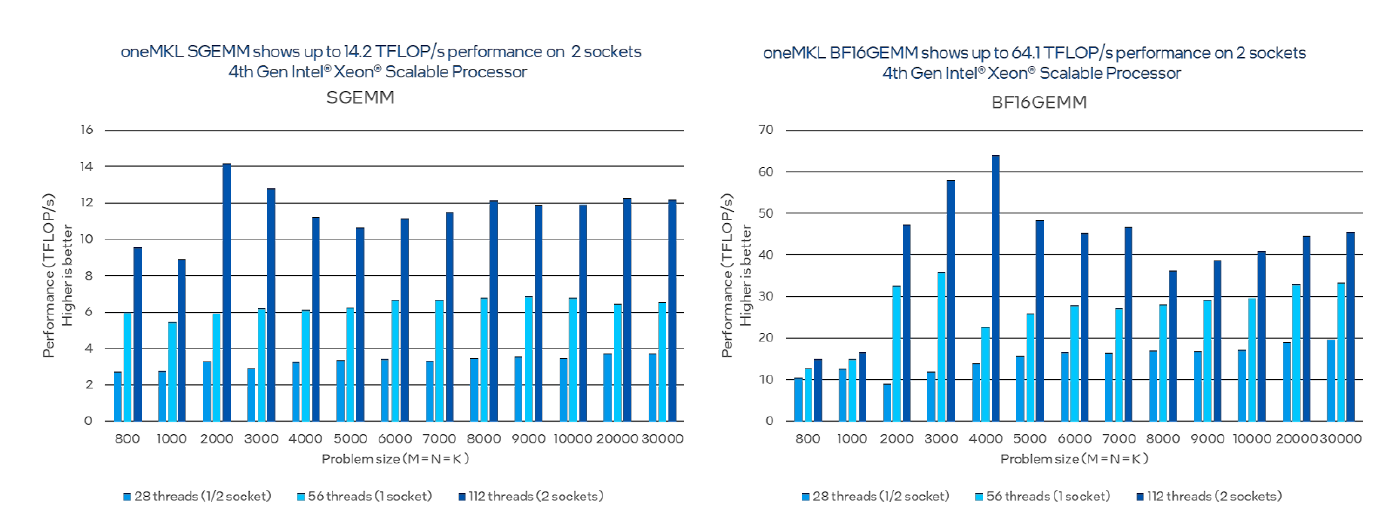
Figure 6. Comparaison des performances de la multiplication matricielle en utilisant les types de données fp32 et bfloat16
Test: Les résultats de performance sont validés avec la version 2024.0 et aucune régression de performance n'est observée par rapport à la version 2023.x.
Détails de la configuration et de la charge de travail: 1 noeud, 2 processeurs Intel® Xeon® Platinum 8480+ sur la plateforme Denali Pass avec 1024 Go (16 slots/ 64GB/ 4800) de mémoire DDR5 au total, ucode 0x2b000161, HT off, Turbo on, Ubuntu 22.04.1 LTS, 5.17.0-051700-generic, 1x Intel SSD 3.5TB OS Drive ; Intel® oneAPI Math Kernel Library 2023.0 (oneMKL). Performances de SGEMM et BFLOAT16GEMM pour des matrices carrées de dimensions comprises entre 800 et 30 000. Les résultats des performances sont basés sur des tests effectués aux dates indiquées dans les configurations et peuvent ne pas refléter toutes les mises à jour publiquement disponibles. Pour plus de détails, voir la divulgation de la configuration. Aucun produit ou composant ne peut être absolument sûr. Les performances varient en fonction de l'utilisation, de la configuration et d'autres facteurs. Pour en savoir plus, consultez le site www.Intel.com/PerformanceIndex. Les coûts et les résultats peuvent varier. Avis et clauses de non-responsabilité Les performances varient en fonction de l'utilisation, de la configuration et d'autres facteurs. Pour en savoir plus, consultez le site Performance Index. Les résultats des performances sont basés sur des tests effectués aux dates indiquées dans les configurations et peuvent ne pas refléter toutes les mises à jour publiquement disponibles. Voir la sauvegarde pour les détails de la configuration. Aucun produit ou composant ne peut être sûr. Les coûts et les résultats peuvent varier. Les technologies Intel peuvent nécessiter l'activation de matériel, de logiciel ou de service.© Intel Corporation. Intel, le logo Intel et les autres marques Intel sont des marques déposées d'Intel Corporation ou de ses filiales. D'autres noms et marques peuvent être revendiqués comme étant la propriété de tiers.
Détails de la configuration: un Intel® Data Center GPU Max 1550 hébergé sur un processeur Intel Xeon 8480+ à deux sockets, 512 Go DDR5-4800, Ubuntu 22.04, Kernel 5.15, IFWI 2023WW28, oneMKL
2023.1, ICX 2023.1.
Analyse des performances pour Intel XMX
Nous allons maintenant étudier les avantages d'Intel XMX sur les GPU Intel en utilisant le benchmark GEMM oneMKL. oneMKL supporte plusieurs algorithmes pour accélérer les GEMM en simple précision via Intel XMX. Bfloat16x2 et bfloat16x3 sont deux de ces algorithmes qui utilisent le matériel systolique bfloat16 pour approximer les GEMM en simple précision. En interne, les données d'entrée en simple précision sont converties en bfloat16 et multipliées avec le tableau systolique. Les trois variantes - bfloat16, bfloat16x2 et bfloat16x3 - vous permettent de choisir un compromis entre précision et performance, bfloat16 étant le plus rapide et bfloat16x3 le plus précis (similaire au GEMM standard). Cependant, ces trois méthodes sont plus performantes que la méthode float standard (figure 7).
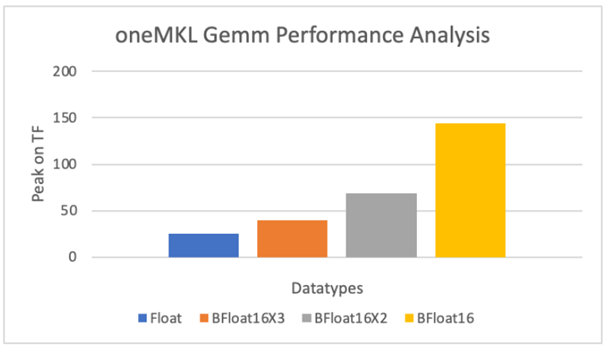
Figure 7. Analyse comparative des performances de oneMKL GEMM pour différents types de données et d'algorithmes
Détails de la configuration: un Intel® Data Center GPU Max 1550 hébergé sur un processeur Intel® Xeon® 8480+ à deux sockets, 512 Go DDR5-4800, Ubuntu 22.04, Kernel 5.15, IFWI 2023WW28, Intel® oneAPI Math Kernel Library 2023.1 (oneMKL), ICX 2024.0. Code utilisé à partir de https://github.com/oneapi-src/oneAPI-samples/tree/master/Libraries/oneMKL/matrix_mul_mkl
Avis et clauses de non-responsabilité: Les performances varient en fonction de l'utilisation, de la configuration et d'autres facteurs. Pour en savoir plus, consultez le site Performance Index. Les résultats des performances sont basés sur des tests effectués aux dates indiquées dans les configurations et peuvent ne pas refléter toutes les mises à jour publiquement disponibles. Voir la sauvegarde pour les détails de la configuration. Aucun produit ou composant ne peut être sûr. Les coûts et les résultats peuvent varier. Les technologies Intel peuvent nécessiter l'activation de matériel, de logiciel ou de service.© Intel Corporation. Intel, le logo Intel et les autres marques Intel sont des marques déposées d'Intel Corporation ou de ses filiales. D'autres noms et marques peuvent être revendiqués comme étant la propriété de tiers.
Conclusion
Cet article donne un aperçu des jeux d'instructions Intel AMX et Intel XMX introduits dans les derniers processeurs et GPU Intel. Les jeux d'instructions Intel AMX et Intel XMX peuvent être invoqués à différents niveaux de programmation, depuis les intrinsèques du compilateur jusqu'à l'abstraction de la matrice commune SYCL, en passant par oneMKL et oneDNN. Plus le paradigme de codage est abstrait, plus il est facile d'invoquer ces jeux d'instructions et moins le programmeur a de contrôle sur l'invocation. Intel AMX et Intel XMX améliorent les performances. L'exemple du benchmark GEMM sur le processeur Intel Xeon Scalable de 4ème génération montre clairement comment les performances sont améliorées par la simple utilisation des types de données de basse précision appropriés et l'invocation d'Intel AMX. De même, l'exemple du benchmark GEMM sur le Intel Data Center GPU Max 1550 montre clairement comment les performances sont boostées en utilisant simplement les types de données de basse précision appropriés et en invoquant Intel XMX. En raison de ses avantages en termes de performances, de sa facilité d'utilisation et de sa capacité à être programmée par le biais d'une programmation de bas niveau, ainsi que par le biais de bibliothèques et de cadres, il est recommandé aux utilisateurs de tester et d'utiliser ces extensions dans leurs charges de travail d'intelligence artificielle.
Nos contenus similaires
 Vidéos
Vidéos
[REPLAY WEBINAIRE] 12 Questions que tout DSI se pose sur Windows 11, l’IA et la modernisation de son parc IT.
 Livres blancs
Livres blancs
[GUIDE] Révolution IA au bureau : Transformez vos postes de travail en moteurs de performance.
Livres blancs
[GUIDE] Environnement de travail : Du matériel aux logiciels, comment alléger la charge des DSI et améliorer l’expérience utilisateur ?
Vidéos
[REPLAY WEBINAIRE] le 22.05 — Design, IA & mobilité : le duo Adobe x Samsung au service de la créativité
Vidéos
[REPLAY WEBINAIRE] — Data + IA : Comment Azure OpenAI et Azure Data Factory transforment vos pipelines de données ?
Livres blancs
[GUIDE] Automatiser et sécuriser la gestion des documents juridiques : quelles solutions pour quels besoins ?
Livres blancs
[GUIDE] Libérez une productivité sécurisée en activant les outils d'entreprise prêts pour l'IA avec Microsoft 365.
 Évènements
Évènements
[WEBINAIRE] le 20.03 — Windows 10 arrive en fin de vie : comment gérer correctement sa migration ?
Notre philosophie
Nous contacter
Une question ? Notre équipe vous répond.
Notre support s'engage à être joignable rapidement et à réagir dans les plus brefs délais. Nous répondons à vos demandes avec rapidité et fiabilité.
Besoin d'en discuter ?
Appelez au 01 53 38 20 50
Notre newsletter
Recevez les #better actualités du software


